


Excessive‑QPS microservices typically endure from fan‑out request patterns: a single person request triggers dozens to lots of of downstream calls, amplifying latency and cargo. This text presents a generic structure that replaces per‑request fan‑out with context prefetching: fetch secure person context and coverage/rule knowledge as soon as (per session or brief time window), then carry out native eligibility analysis throughout many targets (e.g., retailers, gadgets, or companions). In load checks on a big client platform, this method diminished downstream QPS by an order of magnitude, improved tail latency, and lowered compute consumption. This text outlines the design, rollout technique, and commerce‑offs, and positions the method throughout the microservices literature. The approach enhances broadly used microservice types (API gateway, asynchronous messaging/eventing) and mitigates tail‑latency amplification described in prior work.
Background: Why Fan‑Out Hurts at Scale
Microservices excel at modularity and unbiased deployment, however distributed coordination introduces latency variability and failure modes. When a request followers out to many companies (e.g., an eligibility examine for a person throughout N targets), the tip‑to‑finish latency is dominated by the slowest sub‑name. As fan‑out width grows, tail latency grows disproportionately, even when most calls are quick—an impact properly documented in giant‑scale programs.
The microservices literature catalogs these high quality‑attribute commerce‑offs and typical constructions (e.g., gateways, message brokers, database‑per‑service) that groups undertake to stability autonomy with efficiency and reliability. Surveys and mapping research present recurring issues: inter‑service communication overhead, monitoring/observability, and knowledge possession boundaries.
Literature Overview
Within the realm of microservices, Dragoni et al. delve into the evolution of this architectural model, figuring out challenges associated to composition and reliability. Additional insights into frequent architectural patterns comparable to API gateways, asynchronous messaging, and database-per-service, together with their related high quality trade-offs in industrial contexts, are supplied by systematic mappings from Alshuqayran et al. and Taibi et al. Actual-world migration practices, together with ache factors in coordination and observability (particularly for changing fan-out paths), are investigated by Malavolta et al. Lastly, Dean & Barroso contribute a theoretical basis for lowering p99 latency in parallel RPCs, notably exacerbated by in depth fan-out, and suggest designs that intention to scale back variance, informing approaches like prefetch + native analysis.
Downside Assertion
A request arrives to assemble a ranked listing of targets (e.g., shops, gadgets, or companions) for a particular person. The system should show which targets confer which advantages (e.g., free supply, reductions, premium options). A naïve implementation queries a “profit/coverage service” for every (person, goal) pair. Underneath excessive QPS and extensive fan‑out, this balloons into extreme downstream calls, saturating community and CPU, and pushing p99 latency into unacceptable ranges—exactly the “tail at scale” situation.
Context Prefetching + Native Analysis
Design aim: Get rid of per‑goal person lookups and decrease cross‑service hops.
Key concepts
To make sure a seamless and responsive person expertise, notably underneath various community circumstances and system hundreds, we suggest a multi-faceted method to eligibility (person, goal) analysis. This technique focuses on optimizing knowledge fetching and localized processing.
Prefetch and Cache Steady Person Context:
To optimize eligibility checks, proactively retrieve and retailer secure person attributes, forming a “secure person context.” This foundational dataset ought to embrace person memberships (e.g., premium, beta), entitlements, function flags (e.g., A/B take a look at teams), and cohort attributes (e.g., geographical area, person phase). Prefetching ought to happen as soon as per person session or with a brief Time-To-Reside (TTL) to make sure knowledge freshness with out extreme re-fetching. This caching considerably reduces latency by minimizing redundant community calls, enhancing response instances for eligibility checks, and lessening the load on backend person attribute administration companies.
Bulk Fetch and Cache Goal-Facet Coverage/Rule Bundles:
The proposed method includes consolidating insurance policies and guidelines into complete bundles. These bundles are subsequently retrieved and utilized primarily based on segments, areas, or variations, moderately than being fetched individually. This technique necessitates sturdy native caching coupled with efficient invalidation mechanisms to make sure coverage forex. The benefits embody a discount in distant calls, expedited coverage analysis, and diminished community overhead, notably when an orchestrator assesses eligibility for a number of targets.
Consider Eligibility Regionally with a Shared Library/SDK:
To enhance effectivity, eligibility analysis shifts from distant companies to an area part (orchestrator or edge aggregator). This native analysis makes use of an SDK with pre-fetched person context and cached coverage bundles to examine constraints. The SDK, a light-weight and optimized embedded determination engine, eliminates exterior service calls, lowering latency, enhancing resilience, and enabling quicker coverage deployment by SDK or coverage bundle updates.
This method works by optimizing name graphs, managing latency, and lowering computational overhead. It flattens the decision graph from O(N) to O(1) or O(okay) per-request calls, minimizing community requests and processing steps. This additionally reduces tail latency by lowering community hops, resulting in extra constant p99 and p99.9 latency. Compute effectivity is improved by working heavy eligibility logic as soon as per request set as a substitute of for every entity, considerably reducing Question Per Second (QPS) for downstream companies. These advantages align with distributed programs ideas, as highlighted in analysis like “The Tail at Scale,” by lowering latency amplification and variance.
Structure Overview
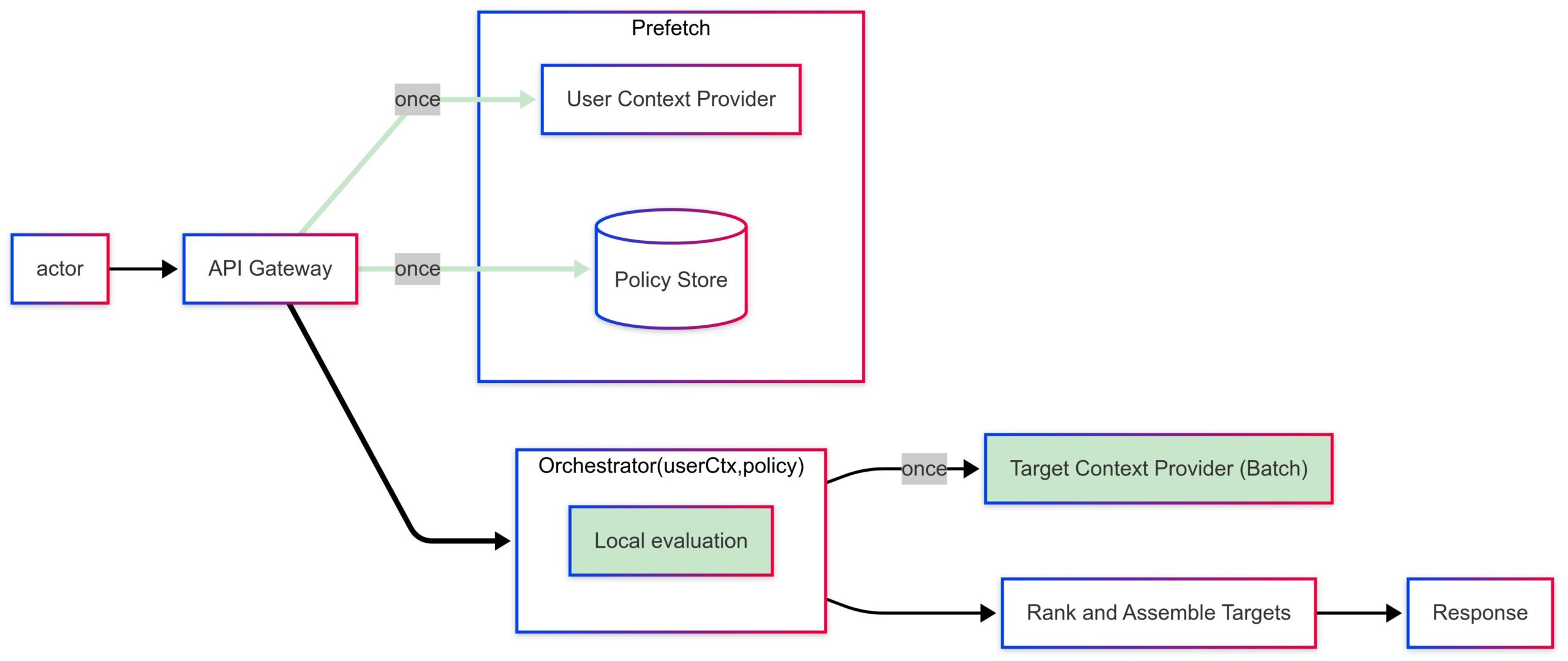
A conveyable blueprint that matches frequent microservice types:
Ingress/API Gateway receives the person request and forwards it to an orchestrator (generally is a BFF or aggregator service). API gateways and BFF patterns are broadly reported in microservice sample surveys.
Prefetch layer pulls person context from an identification/entitlement service with a session‑scoped TTL.
Coverage cache maintains versioned coverage/rule bundles for targets (refreshed through pub/sub or timed pulls). Asynchronous messaging for decoupled updates is a frequent sample in industrial microservices.
Native eligibility engine (library/SDK) deterministically evaluates (user_context, policy_bundle, target_attributes) per goal.
Observability captures cache hit charges, analysis latency, and divergence vs. floor fact to control TTLs and correctness.
Microservice mapping research emphasize that such compositions (gateway + async messaging + database‑per‑service) enhance maintainability and efficiency when communication is fastidiously managed.
Analysis
In pre‑manufacturing and manufacturing canary checks on a excessive‑visitors client workload:
Downstream QPS dropped by roughly an order of magnitude (fan‑out eradicated; most calls served from prefetch or cache).
Tail latency (p99) improved materially because of fewer parallel RPCs and diminished variance sources.
Compute financial savings accrued each within the orchestrator (batch analysis) and downstream programs (fewer invocations).
These outcomes are according to principle and empirical observations on tail‑latency habits in extensive fan‑outs.
Commerce‑offs & Danger Mitigation
Staleness vs. Freshness: Prefetching introduces TTL selections; mitigated with brief TTLs for delicate attributes, versioned coverage bundles, and occasion‑pushed invalidation.
Correctness Drift: Guard with parity shadowing, canarying, and automatic diff alerts till error charges are close to zero.
Complexity Focus: The orchestrator turns into smarter; hold the native analysis library small, deterministic, and properly‑examined.
Observability: Embody per‑determination hint tags and cache metrics; mapping research persistently establish observability as vital in microservices.
Conclusion
Context prefetching converts an N‑means fan‑out right into a compact, cache‑pleasant analysis loop. For top‑QPS programs that should annotate many targets per person request, it meaningfully shrinks downstream QPS, improves tail latency, and reduces compute—whereas aligning with established microservice patterns. As platforms proceed to decompose into finer companies, methods that cut back variance and hops will stay central to assembly strict SLOs at scale.
References
Dean, J., & Barroso, L. A. The Tail at Scale. Communications of the ACM (2013).
Dragoni, N., et al. Microservices: Yesterday, At this time, and Tomorrow. Springer (2017).
Alshuqayran, N., Ali, N., & Evans, R. A Systematic Mapping Examine in Microservice Structure. IEEE SOCA (2016).
Taibi, D., Lenarduzzi, V., & Pahl, C. Architectural Patterns for Microservices: A Systematic Mapping Examine. CLOSER (2018).
Malavolta, I., et al. Migrating in the direction of Microservice Architectures: an Industrial Survey. ICSA (2018).

















 – Neural Networks – 4 November 2025")

{kind=link}